上一节,我们学习了ArrayList 类,本节我们来学习一下LinkedList,LinkedList相对ArrayList而言其使用频率并不是很高,因为其访问元素的性能相对于ArrayList而言比较慢,至于原因我们下面讲开始讲解,本节重点是了解其内部的结构,会简单实现一个简单的LinkedList 即可。
一、LinkedList的简单使用
任何代码在深入分析前,首先需要会使用,因此我们先看下基本的使用列子:
package study.collection;import java.util.LinkedList;public class TestLinkedList { public static void main(String[] args) { // 测试LinkedList的API testLinkedListAPIs() ; // 将LinkedList当作 LIFO(后进先出)的堆栈 useLinkedListAsLIFO(); // 将LinkedList当作 FIFO(先进先出)的队列 useLinkedListAsFIFO(); } /* * 测试LinkedList中部分API */ private static void testLinkedListAPIs() { String val = null; //LinkedList llist; //llist.offer("10"); // 新建一个LinkedList LinkedList llist = new LinkedList(); //---- 添加操作 ---- // 依次添加1,2,3 llist.add("1"); llist.add("2"); llist.add("3"); // 将“4”添加到第一个位置 llist.add(1, "4"); System.out.println("\nTest \"addFirst(), removeFirst(), getFirst()\""); // (01) 将“10”添加到第一个位置。 失败的话,抛出异常! llist.addFirst("10"); System.out.println("llist:"+llist); // (02) 将第一个元素删除。 失败的话,抛出异常! System.out.println("llist.removeFirst():"+llist.removeFirst()); System.out.println("llist:"+llist); // (03) 获取第一个元素。 失败的话,抛出异常! System.out.println("llist.getFirst():"+llist.getFirst()); System.out.println("\nTest \"offerFirst(), pollFirst(), peekFirst()\""); // (01) 将“10”添加到第一个位置。 返回true。 llist.offerFirst("10"); System.out.println("llist:"+llist); // (02) 将第一个元素删除。 失败的话,返回null。 System.out.println("llist.pollFirst():"+llist.pollFirst()); System.out.println("llist:"+llist); // (03) 获取第一个元素。 失败的话,返回null。 System.out.println("llist.peekFirst():"+llist.peekFirst()); System.out.println("\nTest \"addLast(), removeLast(), getLast()\""); // (01) 将“20”添加到最后一个位置。 失败的话,抛出异常! llist.addLast("20"); System.out.println("llist:"+llist); // (02) 将最后一个元素删除。 失败的话,抛出异常! System.out.println("llist.removeLast():"+llist.removeLast()); System.out.println("llist:"+llist); // (03) 获取最后一个元素。 失败的话,抛出异常! System.out.println("llist.getLast():"+llist.getLast()); System.out.println("\nTest \"offerLast(), pollLast(), peekLast()\""); // (01) 将“20”添加到第一个位置。 返回true。 llist.offerLast("20"); System.out.println("llist:"+llist); // (02) 将第一个元素删除。 失败的话,返回null。 System.out.println("llist.pollLast():"+llist.pollLast()); System.out.println("llist:"+llist); // (03) 获取第一个元素。 失败的话,返回null。 System.out.println("llist.peekLast():"+llist.peekLast()); // 将第3个元素设置300。不建议在LinkedList中使用此操作,因为效率低! llist.set(2, "300"); // 获取第3个元素。不建议在LinkedList中使用此操作,因为效率低! System.out.println("\nget(3):"+llist.get(2)); // ---- toArray(T[] a) ---- // 将LinkedList转行为数组 String[] arr = (String[])llist.toArray(new String[0]); for (String str:arr) System.out.println("str:"+str); // 输出大小 System.out.println("size:"+llist.size()); // 清空LinkedList llist.clear(); // 判断LinkedList是否为空 System.out.println("isEmpty():"+llist.isEmpty()+"\n"); } /** * 将LinkedList当作 LIFO(后进先出)的堆栈 */ private static void useLinkedListAsLIFO() { System.out.println("\nuseLinkedListAsLIFO"); // 新建一个LinkedList LinkedList stack = new LinkedList(); // 将1,2,3,4添加到堆栈中 stack.push("1"); stack.push("2"); stack.push("3"); stack.push("4"); // 打印“栈” System.out.println("stack:"+stack); // 删除“栈顶元素” System.out.println("stack.pop():"+stack.pop()); // 取出“栈顶元素” System.out.println("stack.peek():"+stack.peek()); // 打印“栈” System.out.println("stack:"+stack); } /** * 将LinkedList当作 FIFO(先进先出)的队列 */ private static void useLinkedListAsFIFO() { System.out.println("\nuseLinkedListAsFIFO"); // 新建一个LinkedList LinkedList queue = new LinkedList(); // 将10,20,30,40添加到队列。每次都是插入到末尾 queue.add("10"); queue.add("20"); queue.add("30"); queue.add("40"); // 打印“队列” System.out.println("queue:"+queue); // 删除(队列的第一个元素) System.out.println("queue.remove():"+queue.remove()); // 读取(队列的第一个元素) System.out.println("queue.element():"+queue.element()); // 打印“队列” System.out.println("queue:"+queue); }} 从上面的代码可以看出,LinkedList的功能非常多,既可以用于存放元素的集合功能,还具备了堆栈的功能,还拥有队列的功能。这均源于其不仅仅实现了List接口还是实现了Queue接口。
但在介绍LinkedList接口前,从名字可以看出LinkedList 即底层采用的是链表的结构,那什么是链表,需要提前有一个认识:顾名思义,链表就和链子一样,每一环都要连接着后边的一环和前边的一环,这样,当我们需要找这根链子的某一环的时候,只要我们能找到链子的任意一环,都可以找到我们需要的那一环。我们看一个图,就能很好的理解了。

在LinkedList中,我们把链子的“环”叫做“节点”,每个节点都是同样的结构。节点与节点之间相连,构成了我们LinkedList的基本数据结构,也是LinkedList的核心。链表又分为单向链表和双向链表,而单向/双向链表又可以分为循环链表和非循环链表,下面简单就这四种链表进行图解说明。

1. 2.单向循环链表
单向循环链表和单向列表的不同是,最后一个节点的next不是指向null,而是指向head节点,形成一个“环”。

1. 3.双向链表
从名字就可以看出,双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
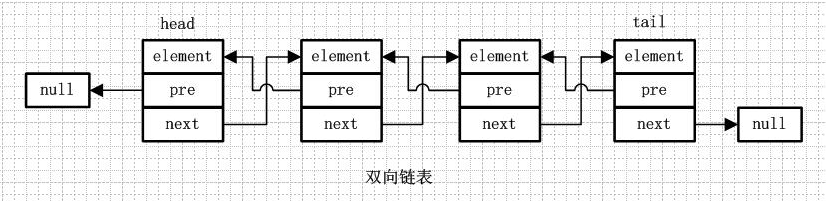

更形象的解释下就是:双向循环链表就像一群小孩手牵手围成一个圈,第一个小孩的右手拉着第二个小孩的左手,第二个小孩的左手拉着第一个小孩的右手。。。最后一个小孩的右手拉着第一个小孩的左手。【接下来我们进入源代码的分析,说明linkedlist 我们采用的JDK1.8进行分析,只所以不用1.6是因为,在1.6 1.7 的时候进行过变动将1.6中的环形结构优化为了直线型了链表结构,然后回到了1.8又有部分的变动,因为从上面可以看出链表的由4种不向ArrayList单一演进,所以这里直接选择用1.8来分析】
二、LinkedList的概述
LinkedList是List和Deque接口的双向链表的实现。实现了所有可选列表操作,并允许包括null值。
LinkedList既然是通过双向链表去实现的,那么它可以被当作堆栈、队列或双端队列进行操作。并且其顺序访问非常高效,而随机访问效率比较低。
注意,此实现不是同步的。 如果多个线程同时访问一个LinkedList实例,而其中至少一个线程从结构上修改了列表,那么它必须保持外部同步。这通常是通过同步那些用来封装列表的 对象来实现的。但如果没有这样的对象存在,则该列表需要运用{@link Collections#synchronizedList Collections.synchronizedList}来进行“包装”,该方法最好是在创建列表对象时完成,为了避免对列表进行突发的非同步操作。
List list = Collections.synchronizedList(new LinkedList(...));
类中的iterator()方法和listIterator()方法返回的iterators迭代器是fail-fast的:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
1.Node节点
private static class Node{ E item; // 当前节点所包含的值 Node next; //下一个节点 Node prev; //上一个节点 Node(Node prev, E element, Node next) { this.item = element; this.next = next; this.prev = prev; } }
2.LinkedList类结构
//通过LinkedList实现的接口可知,其支持队列操作,双向列表操作,能被克隆,支持序列化public class LinkedListextends AbstractSequentialList implements List , Deque , Cloneable, java.io.Serializable{ // LinkedList的大小(指其所含的元素个数) transient int size = 0; /** * 指向第一个节点 * 不变的: (first == null && last == null) || * (first.prev == null && first.item != null) */ transient Node first; /** * 指向最后一个节点 * 不变的: (first == null && last == null) || * (last.next == null && last.item != null) */ transient Node last; ......}
LinkedList包含了三个重要的对象:first、last 和 size。
(1) first 是双向链表的表头,它是双向链表节点所对应的类Node的实例
(2) last 是双向链表的最后一个元素,它是双向链表节点所对应的类Node的实例
(3) size 是双向链表中节点的个数。
3.构造函数
LinkedList提供了两种种方式的构造器,构造一个空列表、以及构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回的顺序排列的。
//构建一个空列表 public LinkedList() { } /** * 构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回的顺序排列的 * @param c 包含用于去构造LinkedList的元素的collection * @throws NullPointerException 如果指定的collection为空 */ //构建一个包含指定集合c的列表 public LinkedList(Collection c) { this(); addAll(c); } 三、LinkedList 方法功能源码分析
/** * LinkedList底层使用双向链表,实现了List和deque。实现所有的可选List操作,并可以只有所有元素(包括空值) * 其大小理论上仅受内存大小的限制 * * 所有的操作都可以作为一个双联列表来执行(及对双向链表操作)。 * 把对链表的操作封装起来,并对外提供看起来是对普通列表操作的方法。 * 遍历从起点、终点、或指定位置开始 * 内部方法,注释会描述为节点的操作(如删除第一个节点),公开的方法会描述为元素的操作(如删除第一个元素) * * LinkedList不是线程安全的,如果在多线程中使用(修改),需要在外部作同步处理。 * * 需要弄清元素(节点)的索引和位置的区别,不然有几个地方不好理解,具体在碰到的地方会解释。 * * 迭代器可以快速报错 */public class LinkedListextends AbstractSequentialList implements List , Deque , Cloneable, java.io.Serializable{ //容量 transient int size = 0; //首节点 transient Node first; //尾节点 transient Node last; //默认构造函数 public LinkedList() { } //通过一个集合初始化LinkedList,元素顺序有这个集合的迭代器返回顺序决定 public LinkedList(Collection c) { this(); addAll(c); } //使用对应参数作为第一个节点,内部使用 private void linkFirst(E e) { final Node f = first;//得到首节点 final Node newNode = new Node<>(null, e, f);//创建一个节点 first = newNode; //设置首节点 if (f == null) last = newNode; //如果之前首节点为空(size==0),那么尾节点就是首节点 else f.prev = newNode; //如果之前首节点不为空,之前的首节点的前一个节点为当前首节点 size++; //长度+1 modCount++; //修改次数+1 } //使用对应参数作为尾节点 void linkLast(E e) { final Node l = last; //得到尾节点 final Node newNode = new Node<>(l, e, null);//使用参数创建一个节点 last = newNode; //设置尾节点 if (l == null) first = newNode; //如果之前尾节点为空(size==0),首节点即尾节点 else l.next = newNode; //如果之前尾节点不为空,之前的尾节点的后一个就是当前的尾节点 size++; modCount++; } //在指定节点前插入节点,节点succ不能为空 void linkBefore(E e, Node succ) { final Node pred = succ.prev;//获取前一个节点 final Node newNode = new Node<>(pred, e, succ);//使用参数创建新的节点,向前指向前一个节点,向后指向当前节点 succ.prev = newNode;//当前节点指向新的节点 if (pred == null) first = newNode;//如果前一个节点为null,新的节点就是首节点 else pred.next = newNode;//如果存在前节点,那么前节点的向后指向新节点 size++; modCount++; } //删除首节点并返回删除前首节点的值,内部使用 private E unlinkFirst(Node f) { final E element = f.item;//获取首节点的值 final Node next = f.next;//得到下一个节点 f.item = null; f.next = null; //便于垃圾回收期清理 first = next; //首节点的下一个节点成为新的首节点 if (next == null) last = null; //如果不存在下一个节点,则首尾都为null(空表) else next.prev = null;//如果存在下一个节点,那它向前指向null size--; modCount++; return element; } //删除尾节点并返回删除前尾节点的值,内部使用 private E unlinkLast(Node l) { final E element = l.item;//获取值 final Node prev = l.prev;//获取尾节点前一个节点 l.item = null; l.prev = null; //便于垃圾回收期清理 last = prev; //前一个节点成为新的尾节点 if (prev == null) first = null; //如果前一个节点不存在,则首尾都为null(空表) else prev.next = null;//如果前一个节点存在,先后指向null size--; modCount++; return element; } //删除指定节点并返回被删除的元素值 E unlink(Node x) { //获取当前值和前后节点 final E element = x.item; final Node next = x.next; final Node prev = x.prev; if (prev == null) { first = next; //如果前一个节点为空(如当前节点为首节点),后一个节点成为新的首节点 } else { prev.next = next;//如果前一个节点不为空,那么他先后指向当前的下一个节点 x.prev = null; //方便gc回收 } if (next == null) { last = prev; //如果后一个节点为空(如当前节点为尾节点),当前节点前一个成为新的尾节点 } else { next.prev = prev;//如果后一个节点不为空,后一个节点向前指向当前的前一个节点 x.next = null; //方便gc回收 } x.item = null; //方便gc回收 size--; modCount++; return element; } //获取第一个元素 public E getFirst() { final Node f = first;//得到首节点 if (f == null) //如果为空,抛出异常 throw new NoSuchElementException(); return f.item; } //获取最后一个元素 public E getLast() { final Node l = last;//得到尾节点 if (l == null) //如果为空,抛出异常 throw new NoSuchElementException(); return l.item; } //删除第一个元素并返回删除的元素 public E removeFirst() { final Node f = first;//得到第一个节点 if (f == null) //如果为空,抛出异常 throw new NoSuchElementException(); return unlinkFirst(f); } //删除最后一个元素并返回删除的值 public E removeLast() { final Node l = last;//得到最后一个节点 if (l == null) //如果为空,抛出异常 throw new NoSuchElementException(); return unlinkLast(l); } //添加元素作为第一个元素 public void addFirst(E e) { linkFirst(e); } //店家元素作为最后一个元素 public void addLast(E e) { linkLast(e); } //检查是否包含某个元素,返回bool public boolean contains(Object o) { return indexOf(o) != -1;//返回指定元素的索引位置,不存在就返回-1,然后比较返回bool值 } //返回列表长度 public int size() { return size; } //添加一个元素,默认添加到末尾作为最后一个元素 public boolean add(E e) { linkLast(e); return true; } //删除指定元素,默认从first节点开始,删除第一次出现的那个元素 public boolean remove(Object o) { //会根据是否为null分开处理。若值不是null,会用到对象的equals()方法 if (o == null) { for (Node x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } //添加指定集合的元素到列表,默认从最后开始添加 public boolean addAll(Collection c) { return addAll(size, c);//size表示最后一个位置,可以理解为元素的位置分别为1~size } //从指定位置(而不是下标!下标即索引从0开始,位置可以看做从1开始,其实也是0)后面添加指定集合的元素到列表中,只要有至少一次添加就会返回true //index换成position应该会更好理解,所以也就是从索引为index(position)的元素的前面索引为index-1的后面添加! //当然位置可以为0啊,为0的时候就是从位置0(虽然它不存在)后面开始添加嘛,所以理所当前就是添加到第一个位置(位置1的前面)的前面了啊! //比如列表:0 1 2 3,如果此处index=4(实际索引为3),就是在元素3后面添加;如果index=3(实际索引为2),就在元素2后面添加。 //原谅我的表达水平,我已经尽力解释了... public boolean addAll(int index, Collection c) { checkPositionIndex(index); //检查索引是否正确(0<=index<=size) Object[] a = c.toArray(); //得到元素数组 int numNew = a.length; //得到元素个数 if (numNew == 0) //若没有元素要添加,直接返回false return false; Node pred, succ; if (index == size) { //如果是在末尾开始添加,当前节点后一个节点初始化为null,前一个节点为尾节点 succ = null; //这里可以看做node(index),不过index=size了(index最大只能是size-1),所以这里的succ只能=null,也方便后面判断 pred = last; //这里看做noede(index-1),当然实现是不能这么写的,看做这样只是为了好理解,所以就是在node(index-1的后面开始添加元素) } else { //如果不是从末尾开始添加,当前位置的节点为指定位置的节点,前一个节点为要添加的节点的前一个节点 succ = node(index); //添加好元素后(整个新加的)的后一个节点 pred = succ.prev; //这里依然是node(index-1) } //遍历数组并添加到列表中 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node newNode = new Node<>(pred, e, null);//创建一个节点,向前指向上面得到的前节点 if (pred == null) first = newNode; //若果前节点为null,则新加的节点为首节点 else pred.next = newNode;//如果存在前节点,前节点会向后指向新加的节点 pred = newNode; //新加的节点成为前一个节点 } if (succ == null) { //pred.next = null //加上这句也可以更好的理解 last = pred; //如果是从最后开始添加的,则最后添加的节点成为尾节点 } else { pred.next = succ; //如果不是从最后开始添加的,则最后添加的节点向后指向之前得到的后续第一个节点 succ.prev = pred; //当前,后续的第一个节点也应改为向前指向最后一个添加的节点 } size += numNew; modCount++; return true; } //清空表 public void clear() { //方便gc回收垃圾 for (Node x = first; x != null; ) { Node next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++; } //获取指定索引的节点的值 public E get(int index) { checkElementIndex(index); return node(index).item; } //修改指定索引的值并返回之前的值 public E set(int index, E element) { checkElementIndex(index); Node x = node(index); E oldVal = x.item; x.item = element; return oldVal; } //指定位置后面(即索引为这个值的元素的前面)添加元素 public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); //如果指定位置为最后,则添加到链表最后 else //如果指定位置不是最后,则添加到指定位置前 linkBefore(element, node(index)); } //删除指定位置的元素, public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } //检查索引是否超出范围,因为元素索引是0~size-1的,所以index必须满足0<=index = 0 && index < size; } //检查位置是否超出范围,index必须在index~size之间(含),如果超出,返回false private boolean isPositionIndex(int index) { return index >= 0 && index <= size; } //异常详情 private String outOfBoundsMsg(int index) { return "Index: "+index+", Size: "+size; } //检查元素索引是否超出范围,若已超出,就抛出异常 private void checkElementIndex(int index) { if (!isElementIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } //检查位置是否超出范围,若已超出,就抛出异常 private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } //获取指定位置的节点 Node node(int index) { //如果位置索引小于列表长度的一半(或一半减一),从前面开始遍历;否则,从后面开始遍历 if (index < (size >> 1)) { Node x = first;//index==0时不会循环,直接返回first for (int i = 0; i < index; i++) x = x.next; return x; } else { Node x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } //获取指定元素从first开始的索引位置,不存在就返回-1 //不能按条件双向找了,所以通常根据索引获得元素的速度比通过元素获得索引的速度快 public int indexOf(Object o) { int index = 0; if (o == null) { for (Node x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; } //获取指定元素从first开始最后出现的索引,不存在就返回-1 //但实际查找是从last开始的 public int lastIndexOf(Object o) { int index = size; if (o == null) { for (Node x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; } //提供普通队列和双向队列的功能,当然,也可以实现栈,FIFO,FILO //出队(从前端),获得第一个元素,不存在会返回null,不会删除元素(节点) public E peek() { final Node f = first; return (f == null) ? null : f.item; } //出队(从前端),不删除元素,若为null会抛出异常而不是返回null public E element() { return getFirst(); } //出队(从前端),如果不存在会返回null,存在的话会返回值并移除这个元素(节点) public E poll() { final Node f = first; return (f == null) ? null : unlinkFirst(f); } //出队(从前端),如果不存在会抛出异常而不是返回null,存在的话会返回值并移除这个元素(节点) public E remove() { return removeFirst(); } //入队(从后端),始终返回true public boolean offer(E e) { return add(e); } //入队(从前端),始终返回true public boolean offerFirst(E e) { addFirst(e); return true; } //入队(从后端),始终返回true public boolean offerLast(E e) { addLast(e);//linkLast(e) return true; } //出队(从前端),获得第一个元素,不存在会返回null,不会删除元素(节点) public E peekFirst() { final Node f = first; return (f == null) ? null : f.item; } //出队(从后端),获得最后一个元素,不存在会返回null,不会删除元素(节点) public E peekLast() { final Node l = last; return (l == null) ? null : l.item; } //出队(从前端),获得第一个元素,不存在会返回null,会删除元素(节点) public E pollFirst() { final Node f = first; return (f == null) ? null : unlinkFirst(f); } //出队(从后端),获得最后一个元素,不存在会返回null,会删除元素(节点) public E pollLast() { final Node l = last; return (l == null) ? null : unlinkLast(l); } //入栈,从前面添加 public void push(E e) { addFirst(e); } //出栈,返回栈顶元素,从前面移除(会删除) public E pop() { return removeFirst(); } /** * Removes the first occurrence of the specified element in this * list (when traversing the list from head to tail). If the list * does not contain the element, it is unchanged. * * @param o element to be removed from this list, if present * @return { @code true} if the list contained the specified element * @since 1.6 */ public boolean removeFirstOccurrence(Object o) { return remove(o); } /** * Removes the last occurrence of the specified element in this * list (when traversing the list from head to tail). If the list * does not contain the element, it is unchanged. * * @param o element to be removed from this list, if present * @return { @code true} if the list contained the specified element * @since 1.6 */ public boolean removeLastOccurrence(Object o) { if (o == null) { for (Node x = last; x != null; x = x.prev) { if (x.item == null) { unlink(x); return true; } } } else { for (Node x = last; x != null; x = x.prev) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } /** * Returns a list-iterator of the elements in this list (in proper * sequence), starting at the specified position in the list. * Obeys the general contract of { @code List.listIterator(int)}. * * The list-iterator is fail-fast: if the list is structurally * modified at any time after the Iterator is created, in any way except * through the list-iterator's own { @code remove} or { @code add} * methods, the list-iterator will throw a * { @code ConcurrentModificationException}. Thus, in the face of * concurrent modification, the iterator fails quickly and cleanly, rather * than risking arbitrary, non-deterministic behavior at an undetermined * time in the future. * * @param index index of the first element to be returned from the * list-iterator (by a call to { @code next}) * @return a ListIterator of the elements in this list (in proper * sequence), starting at the specified position in the list * @throws IndexOutOfBoundsException { @inheritDoc} * @see List#listIterator(int) */ public ListIterator
listIterator(int index) { checkPositionIndex(index); return new ListItr(index); } private class ListItr implements ListIterator { private Node lastReturned; private Node next; private int nextIndex; private int expectedModCount = modCount; ListItr(int index) { // assert isPositionIndex(index); next = (index == size) ? null : node(index); nextIndex = index; } public boolean hasNext() { return nextIndex < size; } public E next() { checkForComodification(); if (!hasNext()) throw new NoSuchElementException(); lastReturned = next; next = next.next; nextIndex++; return lastReturned.item; } public boolean hasPrevious() { return nextIndex > 0; } public E previous() { checkForComodification(); if (!hasPrevious()) throw new NoSuchElementException(); lastReturned = next = (next == null) ? last : next.prev; nextIndex--; return lastReturned.item; } public int nextIndex() { return nextIndex; } public int previousIndex() { return nextIndex - 1; } public void remove() { checkForComodification(); if (lastReturned == null) throw new IllegalStateException(); Node lastNext = lastReturned.next; unlink(lastReturned); if (next == lastReturned) next = lastNext; else nextIndex--; lastReturned = null; expectedModCount++; } public void set(E e) { if (lastReturned == null) throw new IllegalStateException(); checkForComodification(); lastReturned.item = e; } public void add(E e) { checkForComodification(); lastReturned = null; if (next == null) linkLast(e); else linkBefore(e, next); nextIndex++; expectedModCount++; } public void forEachRemaining(Consumer action) { Objects.requireNonNull(action); while (modCount == expectedModCount && nextIndex < size) { action.accept(next.item); lastReturned = next; next = next.next; nextIndex++; } checkForComodification(); } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } } //节点的数据结构,包含前后节点的引用和当前节点 private static class Node { E item; Node next; Node prev; Node(Node prev, E element, Node next) { this.item = element; this.next = next; this.prev = prev; } } //返回迭代器 public Iterator descendingIterator() { return new DescendingIterator(); } //因为采用链表实现,所以迭代器很简单 private class DescendingIterator implements Iterator { private final ListItr itr = new ListItr(size()); public boolean hasNext() { return itr.hasPrevious(); } public E next() { return itr.previous(); } public void remove() { itr.remove(); } } @SuppressWarnings("unchecked") private LinkedList superClone() { try { return (LinkedList ) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(e); } } /** * Returns a shallow copy of this { @code LinkedList}. (The elements * themselves are not cloned.) * * @return a shallow copy of this { @code LinkedList} instance */ public Object clone() { LinkedList clone = superClone(); // Put clone into "virgin" state clone.first = clone.last = null; clone.size = 0; clone.modCount = 0; // Initialize clone with our elements for (Node x = first; x != null; x = x.next) clone.add(x.item); return clone; } /** * Returns an array containing all of the elements in this list * in proper sequence (from first to last element). * * The returned array will be "safe" in that no references to it are * maintained by this list. (In other words, this method must allocate * a new array). The caller is thus free to modify the returned array. * *
This method acts as bridge between array-based and collection-based * APIs. * * @return an array containing all of the elements in this list * in proper sequence */ public Object[] toArray() { Object[] result = new Object[size]; int i = 0; for (Node
x = first; x != null; x = x.next) result[i++] = x.item; return result; } /** * Returns an array containing all of the elements in this list in * proper sequence (from first to last element); the runtime type of * the returned array is that of the specified array. If the list fits * in the specified array, it is returned therein. Otherwise, a new * array is allocated with the runtime type of the specified array and * the size of this list. * * If the list fits in the specified array with room to spare (i.e., * the array has more elements than the list), the element in the array * immediately following the end of the list is set to { @code null}. * (This is useful in determining the length of the list only if * the caller knows that the list does not contain any null elements.) * *
Like the { @link #toArray()} method, this method acts as bridge between * array-based and collection-based APIs. Further, this method allows * precise control over the runtime type of the output array, and may, * under certain circumstances, be used to save allocation costs. * *
Suppose { @code x} is a list known to contain only strings. * The following code can be used to dump the list into a newly * allocated array of { @code String}: * *
* String[] y = x.toArray(new String[0]);* * Note that { @code toArray(new Object[0])} is identical in function to * { @code toArray()}. * * @param a the array into which the elements of the list are to * be stored, if it is big enough; otherwise, a new array of the * same runtime type is allocated for this purpose. * @return an array containing the elements of the list * @throws ArrayStoreException if the runtime type of the specified array * is not a supertype of the runtime type of every element in * this list * @throws NullPointerException if the specified array is null */ @SuppressWarnings("unchecked") publicT[] toArray(T[] a) { if (a.length < size) a = (T[])java.lang.reflect.Array.newInstance(a.getClass().getComponentType(), size); int i = 0; Object[] result = a; for (Node x = first; x != null; x = x.next) result[i++] = x.item; if (a.length > size) a[size] = null; return a; } private static final long serialVersionUID = 876323262645176354L; /** * Saves the state of this { @code LinkedList} instance to a stream * (that is, serializes it). * * @serialData The size of the list (the number of elements it * contains) is emitted (int), followed by all of its * elements (each an Object) in the proper order. */ private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject(); // Write out size s.writeInt(size); // Write out all elements in the proper order. for (Node x = first; x != null; x = x.next) s.writeObject(x.item); } /** * Reconstitutes this { @code LinkedList} instance from a stream * (that is, deserializes it). */ @SuppressWarnings("unchecked") private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject(); // Read in size int size = s.readInt(); // Read in all elements in the proper order. for (int i = 0; i < size; i++) linkLast((E)s.readObject()); } /** * Creates a late-binding * and fail-fast { @link Spliterator} over the elements in this * list. * * The { @code Spliterator} reports { @link Spliterator#SIZED} and * { @link Spliterator#ORDERED}. Overriding implementations should document * the reporting of additional characteristic values. * * @implNote * The { @code Spliterator} additionally reports { @link Spliterator#SUBSIZED} * and implements { @code trySplit} to permit limited parallelism.. * * @return a { @code Spliterator} over the elements in this list * @since 1.8 */ @Override public Spliterator
spliterator() { return new LLSpliterator (this, -1, 0); } /** A customized variant of Spliterators.IteratorSpliterator */ static final class LLSpliterator implements Spliterator { static final int BATCH_UNIT = 1 << 10; // batch array size increment static final int MAX_BATCH = 1 << 25; // max batch array size; final LinkedList list; // null OK unless traversed Node current; // current node; null until initialized int est; // size estimate; -1 until first needed int expectedModCount; // initialized when est set int batch; // batch size for splits LLSpliterator(LinkedList list, int est, int expectedModCount) { this.list = list; this.est = est; this.expectedModCount = expectedModCount; } final int getEst() { int s; // force initialization final LinkedList lst; if ((s = est) < 0) { if ((lst = list) == null) s = est = 0; else { expectedModCount = lst.modCount; current = lst.first; s = est = lst.size; } } return s; } public long estimateSize() { return (long) getEst(); } public Spliterator trySplit() { Node p; int s = getEst(); if (s > 1 && (p = current) != null) { int n = batch + BATCH_UNIT; if (n > s) n = s; if (n > MAX_BATCH) n = MAX_BATCH; Object[] a = new Object[n]; int j = 0; do { a[j++] = p.item; } while ((p = p.next) != null && j < n); current = p; batch = j; est = s - j; return Spliterators.spliterator(a, 0, j, Spliterator.ORDERED); } return null; } public void forEachRemaining(Consumer action) { Node p; int n; if (action == null) throw new NullPointerException(); if ((n = getEst()) > 0 && (p = current) != null) { current = null; est = 0; do { E e = p.item; p = p.next; action.accept(e); } while (p != null && --n > 0); } if (list.modCount != expectedModCount) throw new ConcurrentModificationException(); } public boolean tryAdvance(Consumer action) { Node p; if (action == null) throw new NullPointerException(); if (getEst() > 0 && (p = current) != null) { --est; E e = p.item; current = p.next; action.accept(e); if (list.modCount != expectedModCount) throw new ConcurrentModificationException(); return true; } return false; } public int characteristics() { return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED; } }}
上面的代码解释参考自:http://blog.csdn.net/anxpp/article/details/51203591,感谢anxpp 的分享。
LinkedList和ArrayList的对比:
1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
2、基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
3、数据遍历的速度,看最后一部分,这里就不细讲了,结论是:使用各自遍历效率最高的方式,ArrayList的遍历效率会比LinkedList的遍历效率高一些
4、有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。
从这个分析看出,如果你十分确定你插入、删除的元素是在前半段,那么就使用LinkedList;如果你十分确定你删除、删除的元素在比较靠后的位置,那么可以考虑使用ArrayList。如果你不能确定你要做的插入、删除是在哪儿呢?那还是建议你使用LinkedList吧,因为一来LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;二来插入元素的时候,弄得不好ArrayList就要进行一次扩容,记住,ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作。
四、自己实现一个简单的LinkedList
上面学习了那么多,感觉还是自己来实现一个比较容易理解,并且面试的时候如果考到了,自己写一个简单的即可,理解原理才是最重要的。
1.定义一个Node节点
package study.collection;//用来表示一个节点public class Node { Node previous; //上一个节点 Object obj; Node next; //下一个节点 public Node() { } public Node(Node previous, Object obj, Node next) { super(); this.previous = previous; this.obj = obj; this.next = next; } public Node getPrevious() { return previous; } public void setPrevious(Node previous) { this.previous = previous; } public Object getObj() { return obj; } public void setObj(Object obj) { this.obj = obj; } public Node getNext() { return next; } public void setNext(Node next) { this.next = next; } } 2.定义链表实现
package study.collection;public class MyLinkedList /*implements List*/{ private Node first; //首节点 private Node last; //尾节点 private int size; //个数 public void add(Object obj){ Node n = new Node(); //建立一个新的节点 if(first==null) //如果首节点为空 { n.setPrevious(null); n.setObj(obj); n.setNext(null); first = n; //则这个时候此进入的为第一个元素,那么首节点和尾节点均为新加入的这个节点 last = n; }else{ //直接往last节点后增加新的节点 n.setPrevious(last); //因为这个时候只有一个,那么这个时候往后面添加元素,所以这个时候新加的节点的前节点为last n.setObj(obj); n.setNext(null); last.setNext(n); //原来last的next 节点就是它了 last = n; //n 变成了last } size++; } public int size(){ return size; } private void rangeCheck(int index){ if(index<0||index>=size){ try { throw new Exception(); } catch (Exception e) { e.printStackTrace(); } } } public Object get(int index){ //2 rangeCheck(index); // 0 1 2 3 4 Node temp = node(index); if(temp!=null){ return temp.obj; } return null; } /** * 这个是关键的步骤,根据索引找到对应的节点,这个时候只要遍历即可,而且遍历的 > 1)) { temp = first; for(int i=0;i index; i--){ temp = temp.previous; } } }// LinkedList l; return temp; } public void remove(int index){ Node temp = node(index); if(temp!=null){ Node up = temp.previous; Node down = temp.next; up.next = down; down.previous = up; size--; } } public void add(int index,Object obj){ Node temp = node(index); Node newNode = new Node(); newNode.obj = obj; if(temp!=null){ Node up = temp.previous; up.next = newNode; newNode.previous = up; newNode.next = temp; temp.previous = newNode; size++; } } public static void main(String[] args) { MyLinkedList list = new MyLinkedList(); list.add("aaa"); list.add("bbb");// list.add(1,"BBBB"); list.add("ccc"); list.add("ddd"); list.add("eee");// list.remove(1); System.out.println(list.get(3)); } }
参考资料:
http://www.cnblogs.com/CherishFX/p/4734490.html
http://www.cnblogs.com/tstd/p/5046819.htmlhttp://blog.csdn.net/zw0283/article/details/51132161http://blog.csdn.net/anxpp/article/details/51203591